V tejto časti seriálu sa zameriavame na implementáciu monitoringu ako neoddeliteľnej súčasti správy infraštruktúry. Po úspešnej aktualizácii prostredia prostredníctvom vSphere Lifecycle Managera prichádza na rad zabezpečenie jeho dlhodobej stability a spoľahlivosti. Monitoring má v tomto procese kľúčovú úlohu – od fyzickej kontroly hardvéru servera Cisco UCS C220 M7, cez sledovanie stavu hypervízora ESXi, až po dostupnosť a zdravie vCenter servera.
Prečo monitorovať?
Monitoring nie je len otázkou dobrej správcovskej praxe, ale v mnohých prípadoch aj legislatívnou požiadavkou. Z pohľadu noriem kybernetickej bezpečnosti, ako sú NIS2, ISO 27001 či zákon o kybernetickej bezpečnosti, je povinnosťou prevádzkovateľa infraštruktúry zabezpečiť včasnú detekciu incidentov a prevenciu výpadkov, ktoré by mohli mať dopad na dôvernosť, integritu a dostupnosť dát.
Z pohľadu praxe monitoring umožňuje rýchlo odhaliť potenciálne chyby ešte predtým, ako prerastú do kritických problémov – či už ide o degradované RAID pole, zvyšujúcu sa teplotu CPU, neúspešné zálohy, alebo výpadok sieťovej konektivity na úrovni ESXi.
Syslog a vzdialené logovanie
Súčasťou robustného monitoringu by malo byť aj centralizované logovanie. Konfiguráciou syslog servera (napr. syslog-ng, rsyslog alebo moderných SIEM riešení) dosahujeme to, že všetky systémové logy zo serverov, ESXi a vCenter sú bezpečne uchovávané mimo sledovanej infraštruktúry. To umožňuje nielen efektívnejšiu diagnostiku, ale zároveň napĺňa legislatívne požiadavky na audit a archiváciu prevádzkových záznamov. V prípade incidentu tak máme k dispozícii presný časový prehľad udalostí a systémových stavov.
Záverom, monitoring servera nie je len otázkou technológie – ide o zásadný bezpečnostný a prevádzkový prvok, ktorý znižuje riziká, zvyšuje transparentnosť infraštruktúry a je dôležitým pilierom súladu s platnou legislatívou.
Nastavenie monitoringu pomocou Checkmk
V nadväznosti na predchádzajúce kroky sme pristúpili k implementácii monitoringu, ktorý slúži ako nevyhnutný nástroj na zabezpečenie prehľadu o stave celej infraštruktúry. V tomto prípade sme zvolili riešenie Checkmk, ktoré umožňuje efektívne sledovať fyzické servery, hypervízory ESXi, ako aj samotný vCenter server.
Checkmk podporuje SNMP monitoring, ktorý je ideálny na zber hardvérových metrík zo servera Cisco UCS C220 M7 – ako napríklad stav napájania, teplotné senzory, ventilátory, RAID pole, stav sieťových rozhraní a iné. Pre túto funkcionalitu je potrebné, aby bol na serveri aktivovaný a správne nakonfigurovaný SNMP daemon.
Na úrovni hypervízora ESXi a vCenter servera využívame REST API, ktoré Checkmk natívne podporuje prostredníctvom vlastného pluginu. API komunikácia umožňuje získať údaje o stave jednotlivých virtuálnych strojov, dostupnosti služieb, kapacite diskov, ako aj informácie o výpadkoch a varovaniach v reálnom čase.
Výhody tohto prístupu:
- Agentless monitoring (v prípade SNMP a REST API) zabezpečuje jednoduché nasadenie bez potreby inštalácie klientov na sledované systémy.
- Automatická detekcia služieb – Checkmk si po pridaní hosta sám naskenuje dostupné služby a navrhne, ktoré parametre má sledovať.
- Grafy, prahové hodnoty a notifikácie – umožňujú nielen sledovanie, ale aj rýchle varovanie v prípade odchýlok od normálu.
Príklad konfigurácie:
- Cisco UCS C220 M7 – monitorovaný cez SNMPv2c (prístup pomocou community stringu)
- ESXi hosty – monitorované cez Checkmk vSphere plugin s prístupom cez read-only API používateľa
- vCenter Server Appliance – cez REST API na úrovni služby, databázy a systémových metrík
Týmto monitoringom máme zabezpečený celistvý pohľad na celý reťazec – od hardvéru cez hypervízor až po riadiacu vrstvu. V prípade poruchy alebo výpadku dokážeme rýchlo identifikovať, kde vznikol problém a minimalizovať čas nedostupnosti.
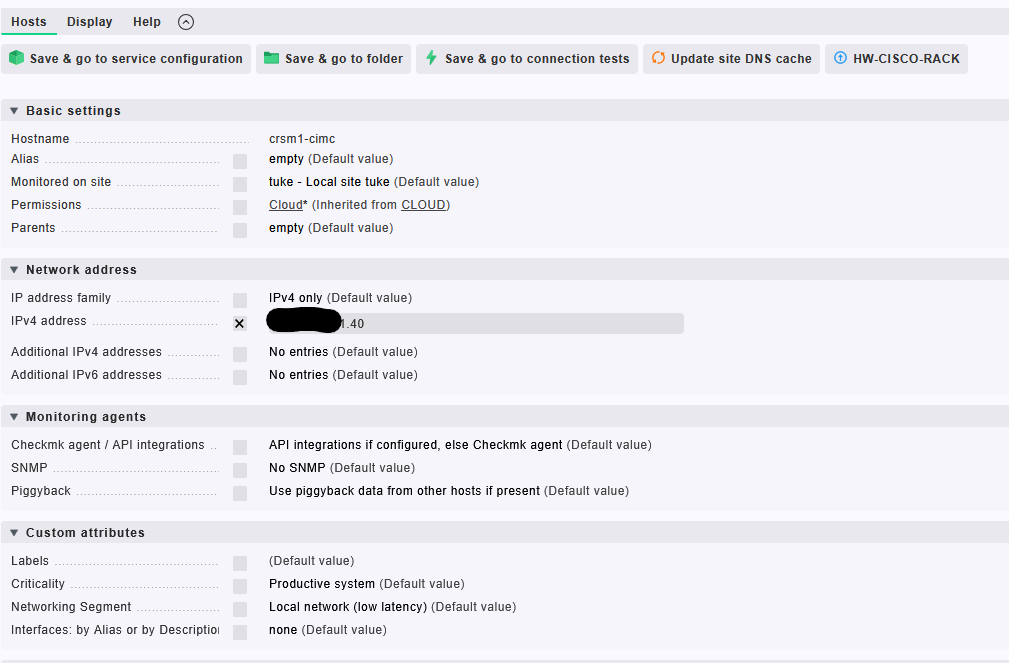
Krok 1: Vytvorenie hosta pre CIMC v Checkmk
V tomto kroku vytvoríme nový host v Checkmk pre fyzický server Cisco UCS C220 M7, konkrétne jeho CIMC rozhranie, ktoré bude následne monitorované pomocou REST – API.
Na obrázku je zobrazená konfigurácia hosta pred pridaním SNMP pravidiel:
- Hostname:
crsm1-cimc– názov pod ktorým bude server vedený v Checkmk - IPv4 address: IP adresa CIMC rozhrania servera (napr.
10.x.x.40) - Checkmk agent / API integrations: predvolené nastavenie (API integrácie alebo agent)
Zatiaľ sme teda vytvorili len základný objekt hosta, bez priamych REST api parametrov.
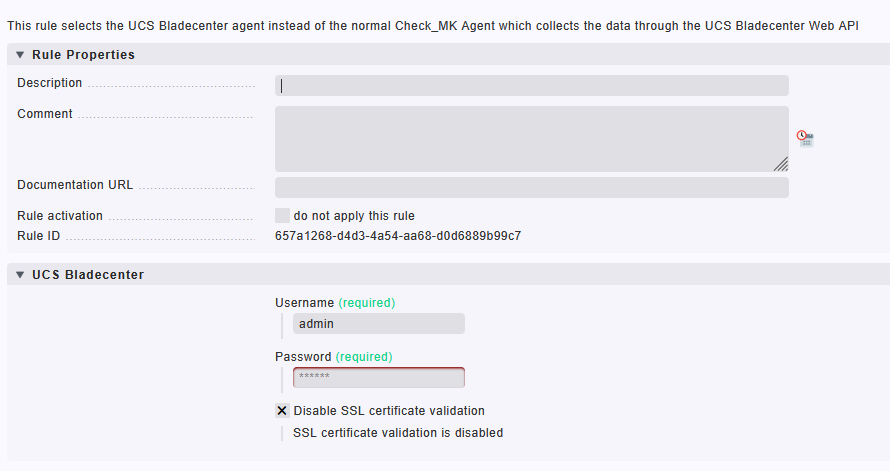
Krok 2: Aktivácia pravidla pre UCS Bladecenter monitoring (CIMC API integrácia)
Po vytvorení hosta je potrebné zmeniť spôsob, akým Checkmk získava dáta z Cisco UCS servera. Namiesto klasického Checkmk agenta alebo SNMP sa v tomto prípade využíva špecializovaný UCS Bladecenter agent, ktorý komunikuje cez UCS Web API (rozhranie CIMC).
Sekcia: Rule Properties
- Description / Comment – voliteľné popisy pravidla (nevyplnené)
- Rule ID – unikátne ID pravidla, ktoré je priradené pri jeho vytvorení (napr.
657a1268-d4d3-4a54-aa68-d0d6889b99c7) - Rule activation – musí byť zaškrtnuté, aby bolo pravidlo aktívne
Sekcia: UCS Bladecenter
- Username – meno používateľa s prístupom do CIMC (napr.
admin) - Password – heslo k účtu (skryté)
- Disable SSL certificate validation – táto voľba je zaškrtnutá, čo znamená, že Checkmk nebude overovať platnosť TLS certifikátu CIMC rozhrania. Táto možnosť je užitočná v prípade, že CIMC používa samopodpísaný certifikát, čo je v interných prostrediach bežné.
Týmto krokom sa zabezpečí, že Checkmk bude získavať hardvérové metriky priamo cez rozhranie Cisco UCS – vrátane informácií ako:
- Stav napájania
- Teplotné senzory
- Stav RAID poľa
- Chyby pamätí a napájania
- Inventár hardvéru
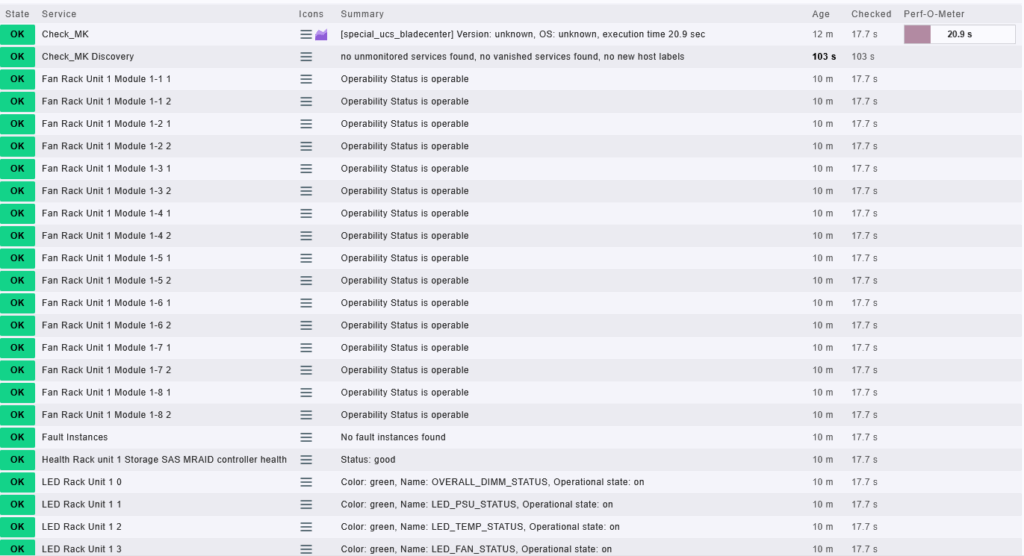
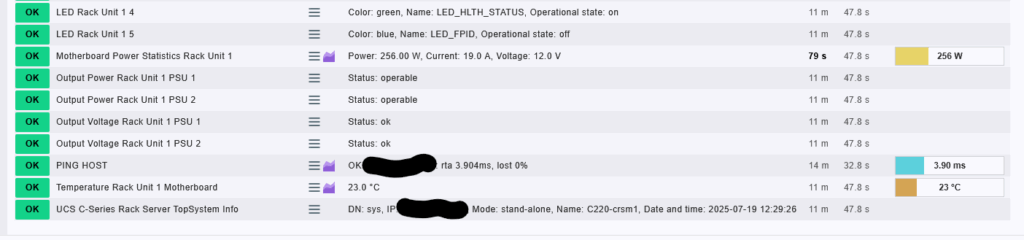
Krok 3: Kontrola monitorovaných služieb na serveri Cisco UCS C220 M7
Po úspešnej aktivácii UCS Bladecenter agenta a pridelení autentifikačných údajov prichádza fáza, v ktorej overujeme, či sa všetky hardvérové komponenty servera správne zobrazujú v systéme Checkmk.
Monitoring beží cez rozhranie Cisco CIMC pomocou špeciálneho API agenta, ktorý poskytuje bohaté informácie o fyzickom stave zariadenia. Medzi najdôležitejšie monitorované služby patria:
Hardvérové senzory a stavy:
Fan Rack Unit 1 Module X-X-X
- Príklad:
Fan Rack Unit 1 Module 1-1-1,1-3-2atď. - Popis: Sledovanie stavu ventilátorov v jednotlivých moduloch. Stav „Operability Status is operable“ znamená, že ventilátor funguje správne.
- Význam: Kritické pre chladenie systému – výpadok by mohol viesť k prehrievaniu.
Temperature Rack Unit 1 Motherboard
- Popis: Teplota základnej dosky – aktuálne 23.0 °C.
- Význam: Umožňuje detekciu prehriatia, ktoré môže signalizovať problém s chladením alebo nadmerným zaťažením.
Health Rack unit 1 Storage SAS MRAID controller health
- Popis: Kontrola zdravia RAID radiča – stav „good“ znamená, že RAID funguje správne.
- Význam: Kritický pre stav diskového poľa – napr. poškodený disk, rebuild, degradačný mód.
LED Rack Unit 1 X
- Popis: Stav indikátorov LED na šasi (napr.
LED_TEMP_STATUS,LED_PSU_STATUS,LED_FAN_STATUS,LED_FPDI). - Význam: Stav signalizačných LED diód (zelené – OK, modré – OFF), pomoc pri fyzickej identifikácii problému.
Napájanie:
Output Power / Voltage / Current – Rack Unit 1 PSU X
- Popis: Výstupné napätie, prúd a výkon pre každé PSU (Power Supply Unit).
- Príklad:
256.00 W,19.0 A,12.0 V - Význam: Monitorovanie spotreby energie – môže pomôcť odhaliť poruchu napájania alebo nadmerné zaťaženie.
Motherboard Power Statistics
- Popis: Agregovaný odber energie matičnej dosky (výkon, prúd, napätie).
- Význam: Pomáha sledovať trendy v spotrebe a identifikovať výkyvy.
Systémové informácie:
UCS C-Series Rack Server TopSystem Info
- Popis: Obsahuje údaje o režime (napr. „stand-alone“), názov servera (
C220-crsm1), dátum a čas. - Význam: Overenie základných systémových metaúdajov z UCS.
PING HOST
- Popis: Dostupnosť servera – latencia (napr. 3.90 ms), strata paketov.
- Význam: Základná sieťová dostupnosť a latencia z pohľadu monitoring servera.
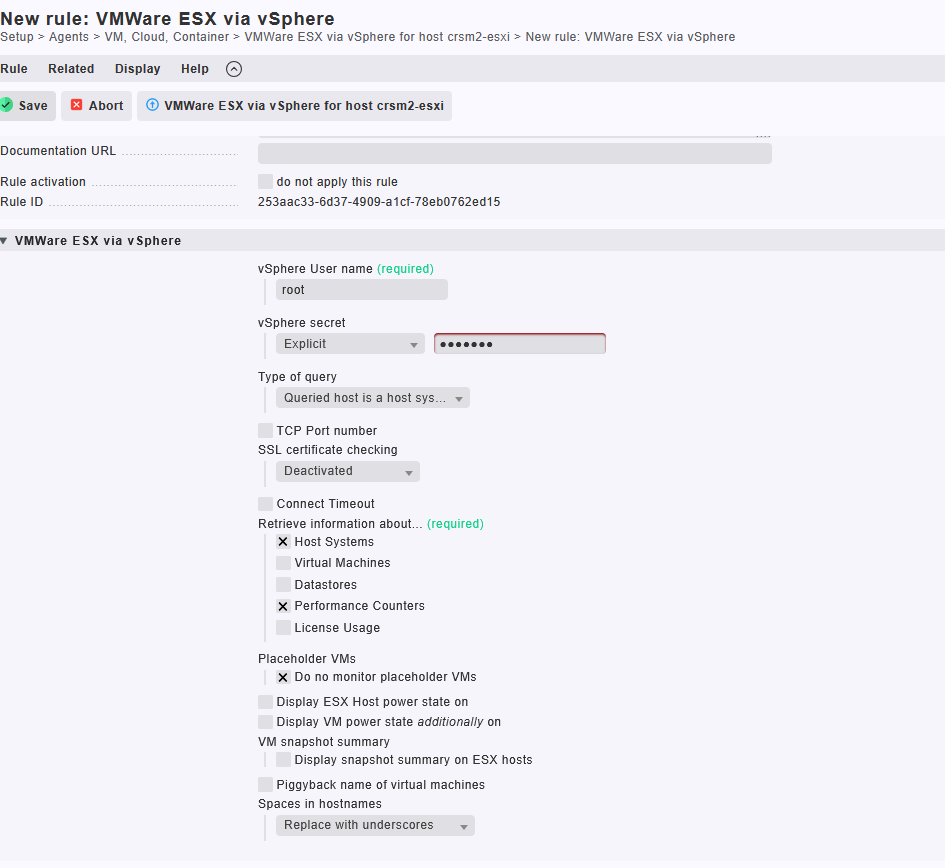
Krok 4: Monitorovanie VMware ESXi hosta cez vSphere API
Správne nakonfigurovaný monitoring ESXi hostov je kľúčový pre prevádzkovú spoľahlivosť celého virtualizačného prostredia. Umožňuje včas detegovať výpadky hardvérových komponentov, preťaženie hosta, nedostatok zdrojov či zmeny vo výkone virtuálnych strojov. Monitoring zároveň slúži ako jeden z dôležitých nástrojov pre audit, troubleshooting a optimalizáciu infraštruktúry.
V Checkmk sa ESXi servery monitorujú pomocou špeciálneho agenta „VMWare ESX via vSphere“, ktorý využíva vSphere Web API na zber dát z hypervízora. Tento spôsob je agentless, teda nevyžaduje inštaláciu softvéru priamo na ESXi.
Na obrázku je ukázané vytvorenie pravidla pre host crsm2-esxi, kde sa definujú nasledovné parametre:
- vSphere User name / secret: prihlasovacie údaje k ESXi (odporúča sa vytvoriť samostatného používateľa s read-only právami)
- SSL certificate checking: vypnuté, ak ESXi používa self-signed certifikát
- Retrieve information about:
- ✅ Host Systems – stav ESXi hosta, jeho CPU, RAM, load atď.
- ✅ Performance Counters – detailné metriky o zaťažení
- Virtual Machines a Datastores: voliteľné podľa potreby
- Do not monitor placeholder VMs – ignorovanie testovacích šablón
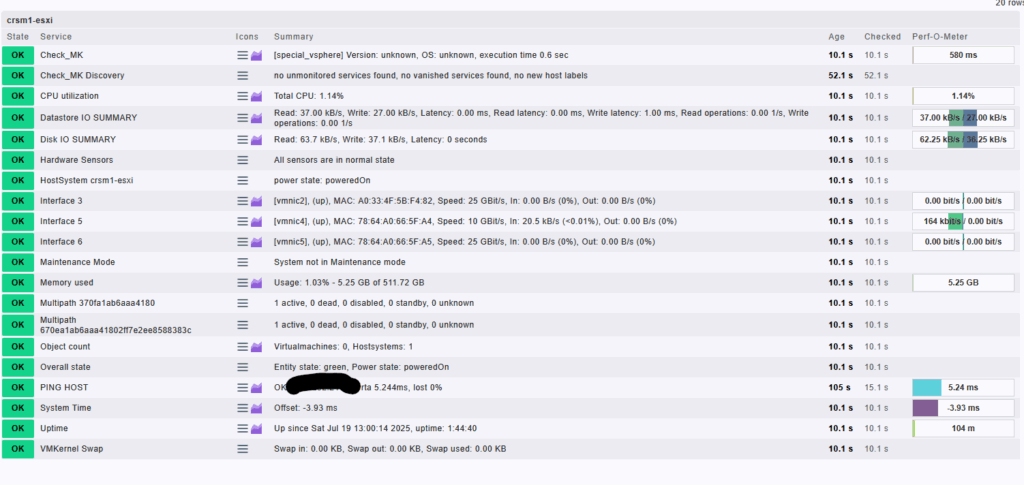
Monitorované služby na ESXi hostovi crsm1-esxi:
Check_MK / Check_MK Discovery
- Check_MK: výstup z vSphere agenta, základné overenie funkcionality
- Discovery: zisťovanie nových služieb – nič nechýba, všetko je monitorované
CPU utilization
- Aktuálne zaťaženie CPU (1.14 %) – umožňuje sledovať výkonový trend a detegovať preťaženie hosta
Datastore IO SUMMARY / Disk IO SUMMARY
- Prenosy na úrovni diskového a dátového úložiska:
- Read/Write rýchlosť (napr. 62.25 kB/s čítanie)
- Latencia a počet IOPS
- Kritické pre sledovanie výkonu storage – akékoľvek spomalenie úložiska ovplyvní všetky VM
Hardware Sensors
- Hardvérové senzory servera (teplota, ventilátory, napájanie…) – všetko je „normal state“
HostSystem crsm1-esxi
- Overenie stavu ESXi hosta:
power state: poweredOn
Interface 3 / 5 / 6
- Monitorovanie sieťových rozhraní (napr.
vmnic4,vmnic5) - Rýchlosť a traffic (napr. 164 kbit/s in na
vmnic4)
Maintenance Mode
- Informácia, či je host v režime údržby – aktuálne „not in maintenance mode“
Memory used
- Využitie operačnej pamäte (napr. 5.25 GB z 511.72 GB)
Multipath (2x)
- Stav storage ciest k LUNom – 1 aktívna, 0 mŕtvych – všetko v poriadku
Object count
- Počet VM bežiacich na tomto hoste (napr. 1 VM)
Overall state
- Celkový stav entít z vSphere – aktuálne:
poweredOn
PING HOST
- ICMP dostupnosť hosta – latencia (napr. 5.24 ms), bez straty paketov
System Time
- Offset systémového času hosta oproti monitorovaciemu serveru (napr. -3.93 ms)
Uptime
- Dĺžka behu hosta od posledného štartu (napr. 1h 44m)
VMKernel Swap
- Informácia o využívaní SWAPu v rámci VMKernel – aktuálne 0.00 KB, čo je ideálne
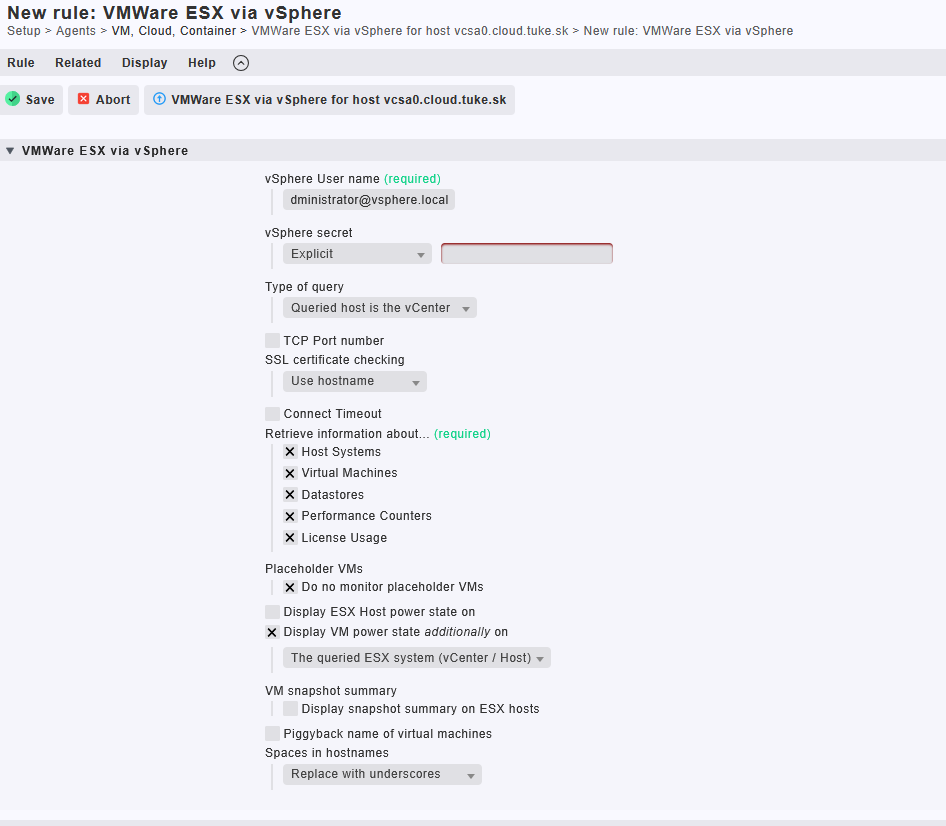
Krok 5: Monitorovanie vCenter Servera cez vSphere API
Po nakonfigurovaní monitoringu fyzického servera a ESXi hostov pokračujeme v nastavení dohľadu nad samotným vCenter Serverom, ktorý zohráva kľúčovú úlohu v celej VMware infraštruktúre. Vďaka monitoringu cez vSphere API dokážeme sledovať nielen samotný vCenter, ale aj všetky ESXi hosty a virtuálne stroje, ktoré sú doň pridané.
Na obrázku vidíme vytváranie pravidla v Checkmk pre vCenter host vcsa0.cloud.tuke.sk:
- vSphere User name: prihlasovací účet s prístupom do vCenter (napr.
administrator@vsphere.local) - Type of query:
Queried host is the vCenter– definuje, že agent bude získavať údaje z centrálneho riadiaceho bodu - Retrieve information about:
- ✅ Host Systems – všetky ESXi servery pod správou vCenter
- ✅ Virtual Machines – stavy, zaťaženie a dostupnosť VM
- ✅ Datastores – kapacita a výkon úložísk
- ✅ Performance Counters – podrobné výkonnostné metriky
- ✅ License Usage – využitie licencií (užitočné pre audit)
- VM power state: zobrazenie stavov VM aj na úrovni vCenter
- Placeholder VMs: vypnuté – testovacie šablóny sa nesledujú
- Snapshot summary: voliteľné zapnutie pre dohľad nad snapshotmi
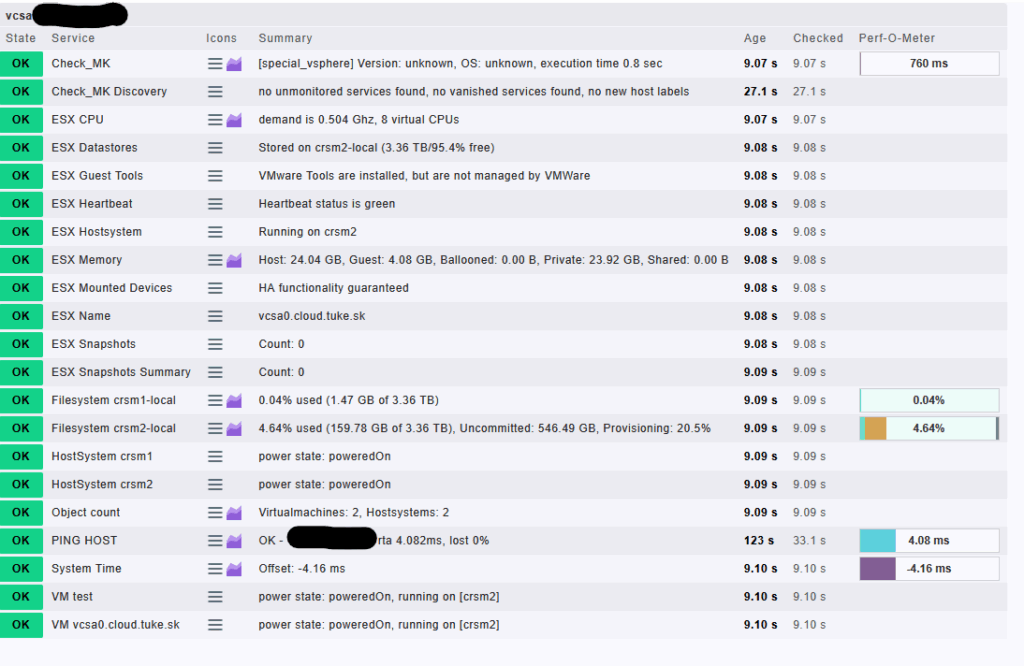
Monitorované služby cez vCenter:
Základný stav a komunikácia:
Check_MKaCheck_MK Discovery– funkčnosť vSphere agenta a zistenie nových služiebPING HOST– latencia a dostupnosť vCenter hostaSystem Time– odchýlka systémového času
Výkonové a prevádzkové parametre:
ESX CPU– aktuálne CPU zaťaženie VM bežiacich na ESXi (napr. 0.504 GHz)ESX Memory– pamäťové využitie (napr. host: 24 GB, guest: 4.08 GB)Object count– počet VM a ESXi hostov (napr. 2 VM, 2 hosty)
Úložisko a snapshoty:
ESX Datastores– kapacita a využitie (napr. 3.36 TB, 95.4 % voľné)Filesystem crsm1-local / crsm2-local– využitie lokálnych filesystemovESX Snapshots / Snapshots Summary– počet snapshotov na hostoch (aktuálne 0)
ESXi hosty a ich stav:
ESX Hostsystem– informácia o tom, na ktorom hoste VM beží (napr. crsm2)ESX Name,ESX Heartbeat,ESX Mounted Devices– identita hosta, heartbeat stav, HA stavHostSystem crsm1,HostSystem crsm2– stav zapnutia jednotlivých ESXi hostov (poweredOn)
Virtuálne stroje:
VM test,VM vcsa0.cloud.tuke.sk– stav VM (poweredOn, beží na crsm2)ESX Guest Tools– či sú VMware Tools nainštalované a funkčné
Tento monitoring zabezpečuje kompletný prehľad o celom virtualizačnom prostredí – od fyzických hostov cez dátové úložiská až po jednotlivé virtuálne stroje. Vďaka tomu je možné rýchlo detegovať problémy, vyhodnocovať výkonnostné trendy a reagovať na zmeny v infraštruktúre.
Krok 6: Monitorovanie samotného vCenter Servera (vCSA)
Popri monitorovaní ESXi hostov a virtuálnych strojov je dôležité nezabúdať ani na samotný vCenter Server – konkrétne na jeho operačný stav, služby a zdravie. V prípade výpadku alebo zhoršeného výkonu vCSA môže dôjsť k strate riadenia nad celou virtualizačnou infraštruktúrou, čo môže výrazne ovplyvniť správu, automatizáciu a dostupnosť služieb.
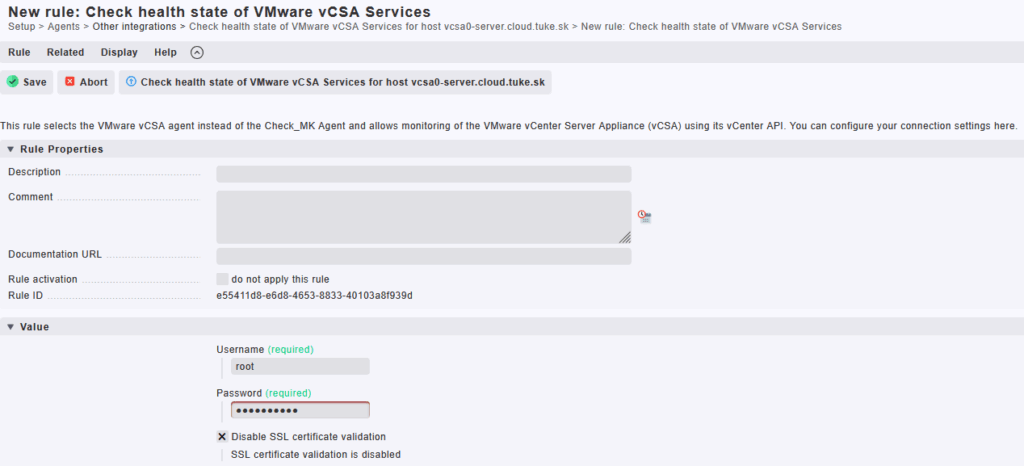
V nástroji Checkmk sa na tento účel používa špeciálny agent „VMware vCSA Services“, ktorý komunikuje priamo cez vCenter API a umožňuje sledovať stav jednotlivých systémových služieb.
Na obrázku je ukázané vytvorenie pravidla pre host vcsa0-server.cloud.tuke.sk, kde zadávame:
- Username / Password: prístup k vCSA (napr. používateľ
root) - Disable SSL certificate validation: zvyčajne zapnuté pri použití samopodpísaného certifikátu
Prečo monitorovať vCenter?
- Prevencia výpadkov – zlyhanie služby
vpxd(hlavný demon vSphere) môže znemožniť správu celej infraštruktúry - Zdravie služieb – vCSA beží na viacerých mikroslužbách (telemetria, SSO, logovanie, backup), ktoré môžu zlyhať samostatne
- Výkon – monitorovanie preťaženia služby, pomalých odoziev alebo zvyšujúcej sa latencie API
- Audit – prehľad o tom, či sú všetky služby funkčné (vrátane zálohovania, prístupov atď.)
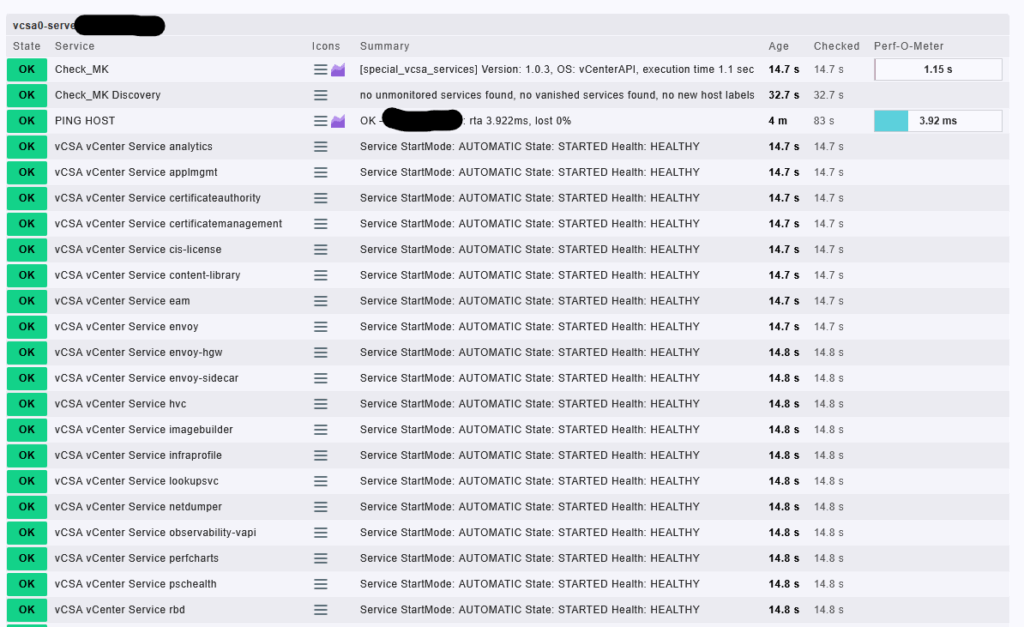
Výsledok monitoringu vCSA
Pomocou špeciálneho vCSA agenta v Checkmk získavame prehľad o všetkých systémových službách bežiacich na vCenter Server Appliance. Agent využíva vCenter API a pravidelne kontroluje:
- stav služby (či bola spustená automaticky a či aktuálne beží),
- zdravie služby (HEALTHY vs. DEGRADED),
- a dostupnosť samotného servera cez ICMP (ping).
Zobrazované sú všetky kľúčové služby, ako napríklad analytics, lookupsvc, content-library, certificateauthority, hvc, netdumper, imagebuilder a ďalšie. Všetky tieto komponenty tvoria základnú funkčnosť vCenter a ich výpadok môže viesť k zníženej dostupnosti, strate funkčnosti alebo problémom pri správe celého prostredia.
Tento typ monitoringu je dôležitý najmä pri zabezpečovaní vysokodostupných riešení, kde je včasná detekcia problémov v riadiacej vrstve rozhodujúca pre prevádzkovú kontinuitu. Služby sú monitorované samostatne a v prípade výpadku jednej z nich je možné okamžite spustiť eskaláciu či servisný zásah.
Krok 7: Zabezpečenie centralizovaného logovania pomocou Syslog
Spoľahlivý monitoring infraštruktúry nie je úplný bez dôkladne nastaveného logovania. V rámci enterprise prostredí je štandardom využívať Syslog ako protokol pre zber systémových a bezpečnostných logov zo všetkých zariadení a systémov. Cieľom je centralizovať záznamy o udalostiach a poruchách pre potreby auditu, forenznej analýzy a okamžitej reakcie na incidenty.
Všetky vrstvy infraštruktúry by mali zasielať logy na centrálne logovacie servery, ideálne aspoň dva – kvôli redundancii a zabezpečeniu dostupnosti v prípade výpadku jedného z nich.
Konfigurácia Syslog na Cisco UCS C220 M7 (CIMC)
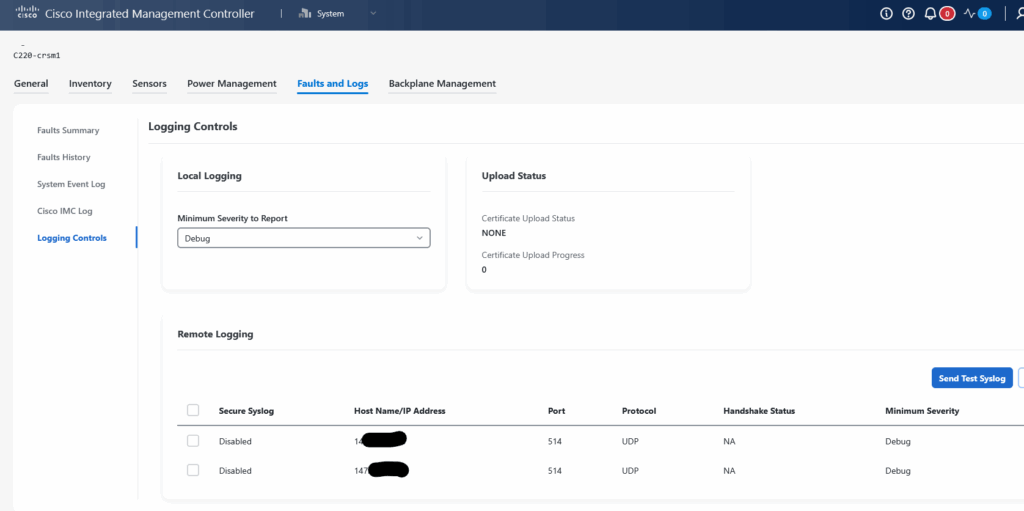
Na priloženom obrázku vidíme nastavenie Cisco Integrated Management Controller (CIMC), kde sa definuje:
- Minimum Severity to Report:
Debug– odosielajú sa všetky správy vrátane detailných (možno neskôr zmeniť naInfoaleboWarning) - Remote Logging: dva zadefinované syslog servery (napr.
147.x.x.1a147.x.x.2) - Protokol:
UDP, port514(štandardný pre syslog) - Secure Syslog: zatiaľ vypnutý, ale odporúčaný v produkčných a citlivých prostrediach
Toto nastavenie zabezpečuje, že CIMC bude odosielať všetky udalosti (poruchy, senzory, napájanie, reštarty) na externé logovacie servery, čím sa eliminuje závislosť na samotnom zariadení pri forenznej analýze.
Konfigurácia Syslog pre vCenter Server (vCSA)
Okrem CIMC je nevyhnutné, aby logy odosielal aj samotný vCenter Server Appliance (vCSA). Ten slúži ako riadiaca jednotka celej VMware infraštruktúry a uchováva množstvo kritických udalostí – od správy hostov, cez zmeny v konfiguráciách až po alarmy, SSO a auditné záznamy.
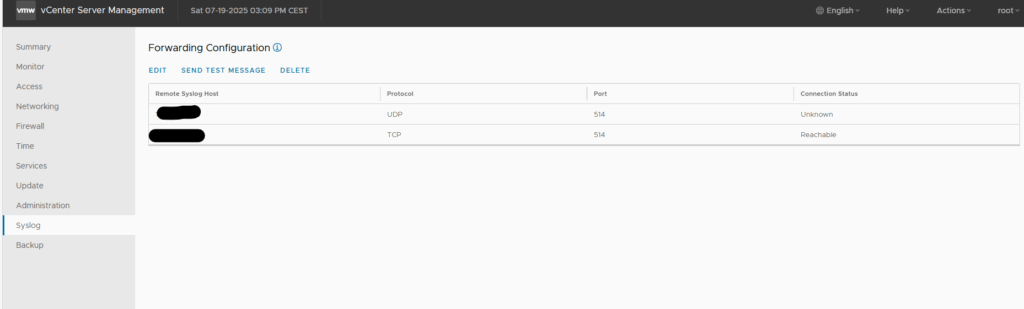
Na obrázku je zobrazené nastavenie forwarding konfigurácie v časti vCenter Server Management > Syslog, kde sú zadefinované:
- Dva vzdialené Syslog servery:
- Jeden cez UDP (514) – stav pripojenia: „Unknown“
- Druhý cez TCP (514) – stav pripojenia: „Reachable“
- Použité sú oba protokoly – UDP je rýchly, no nespoľahlivý; TCP je pomalší, ale zaručuje doručenie (vhodné pre kritické logy)
Týmto nastavením zabezpečíme, že vCSA bude v reálnom čase odosielať logy o svojom stave, službách a systémových udalostiach na centrálny logovací systém. V prostredí, kde prebieha monitoring a audit, je to zásadné pre forenzné účely, detekciu útokov a spätnú analýzu zmien.
Konfigurácia Syslog pre ESXi hosty
Na to, aby bola infraštruktúra kompletne pokrytá logovaním, je nevyhnutné nakonfigurovať aj odosielanie logov z jednotlivých ESXi hostov. Každý host obsahuje množstvo dôležitých systémových informácií: chyby diskových polí, výpadky siete, stavy VMkernelu, konfigurácie siete a ďalšie udalosti, ktoré musia byť uchovávané mimo samotného hosta pre účely auditu a forenznej analýzy.
Na priloženom obrázku vidíme nastavenie v časti Advanced System Settings pre host hp4.cloud.tuke.sk, konkrétne kľúčové parametre:
Syslog.global.logHost
Definuje vzdialené Syslog servery – v tomto prípade dva:
udp://:514, tcp://:514 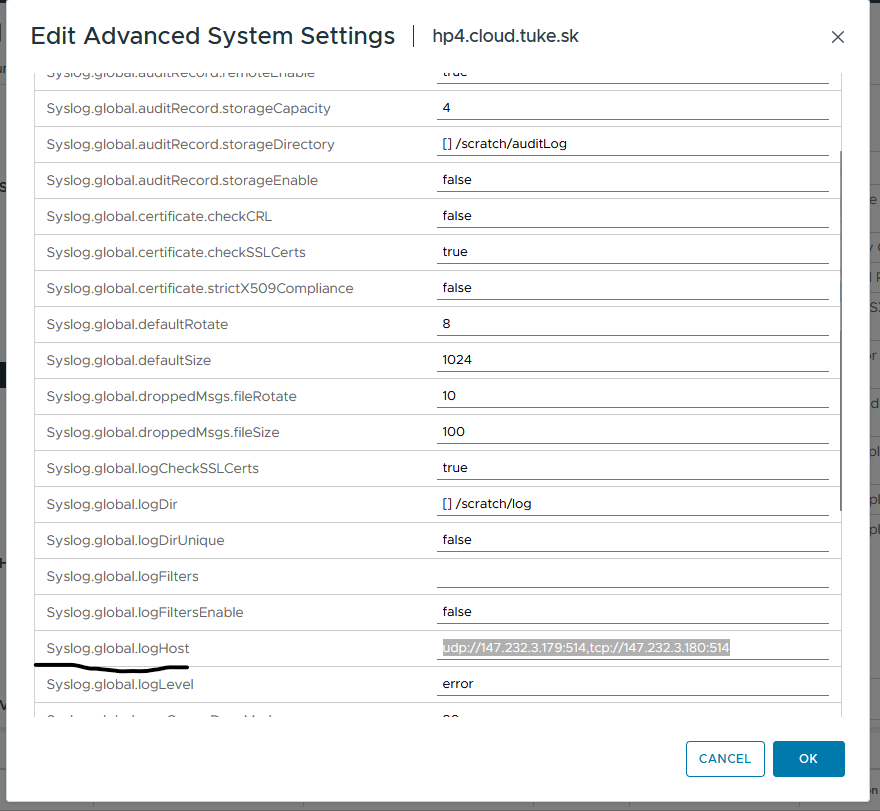

Odborník na kybernetickú bezpečnosť, správu Azure Cloud a VMware onprem. Využíva technológie, ako Checkmk a MRTG, na monitorovanie siete a zvyšovanie efektívnosti a bezpečnosti IT infraštruktúry. Kontakt: hasin(at)mhite.sk